CityRAG Generates a Simulated Environment of a City
Given a random image of San Francisco and a trajectory to drive forward, CityRAG generates a video that reveals the actual buildings on the street.
Controllable Weather and Appearance
Exploration of arbitrary weather and appearance at the same location (S King St, Honolulu).
Loop Closure
Geographically grounded and stable generation around Calle Quiñones St, San Juan with loop closure.
This trajectory (top right corner) is user-defined and not found in our database.
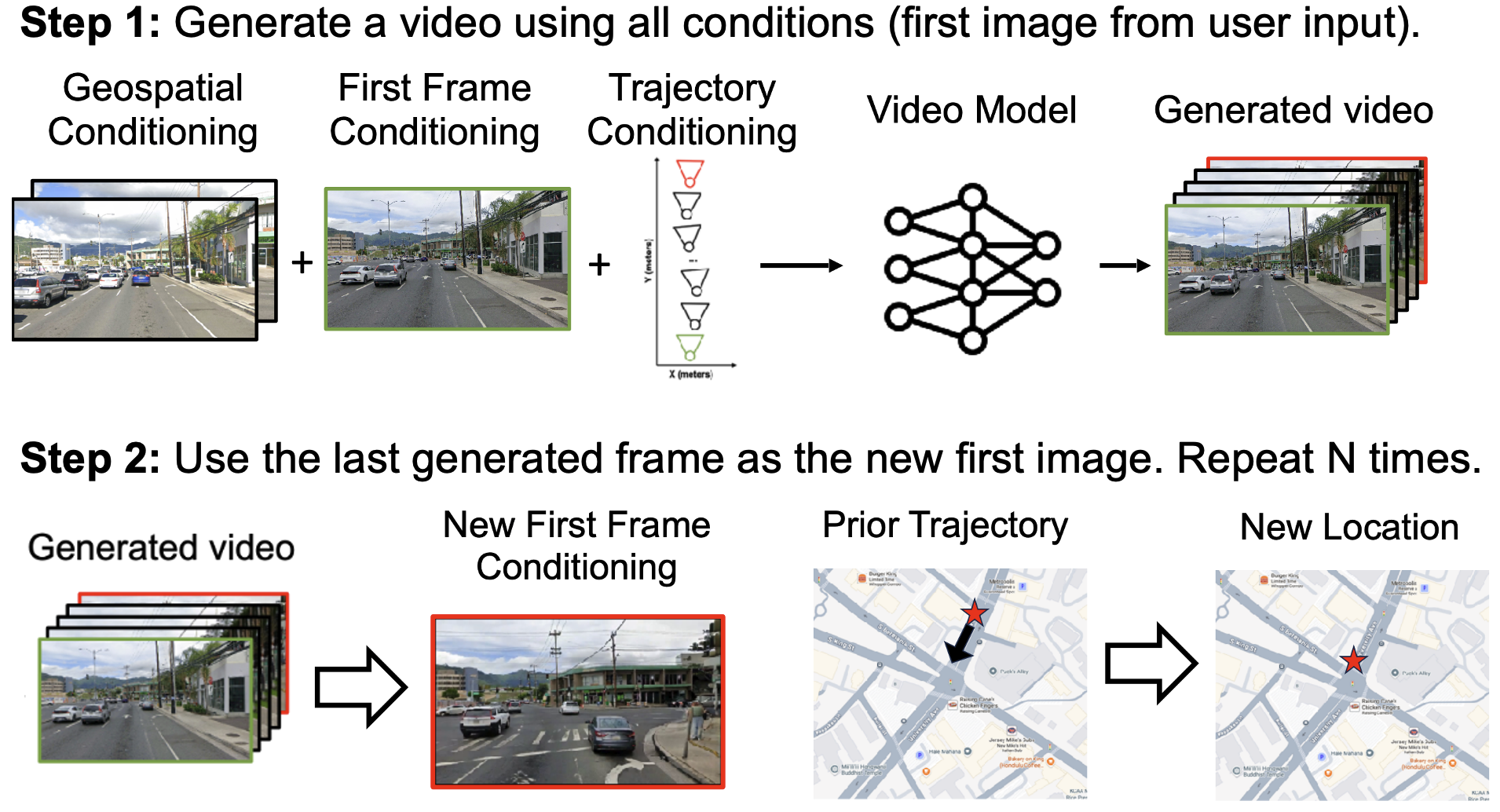
CityRAG generates minutes-long, physically grounded video sequences that
1) reconstruct real buildings and roads; 2) are initialized from a first image and respects its weather conditions and dynamic
objects;
3) follow arbitrary user-defined trajectories and show loop closure.
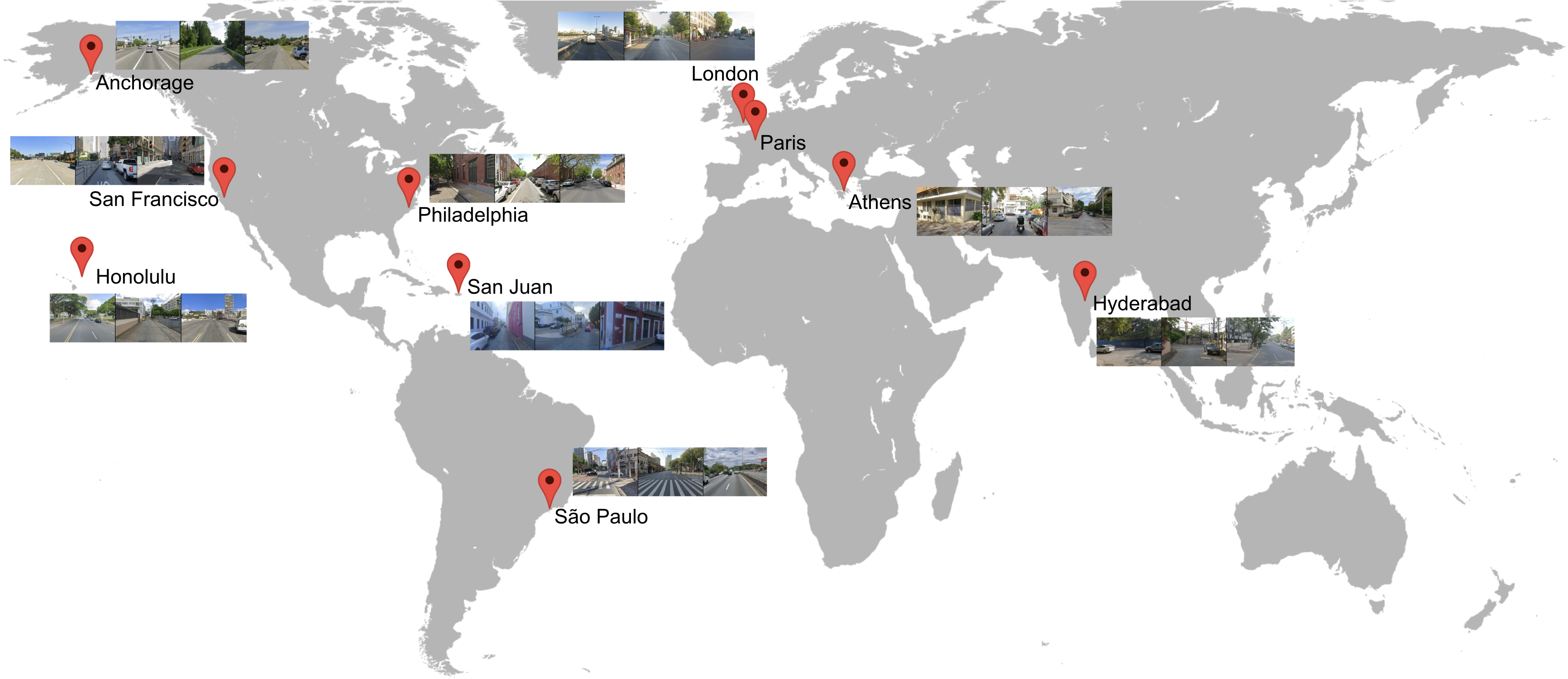
Data
With explicit permission from Google, we collect Street View data from Google Maps across 10 diverse cities scattered across the globe: Paris, Athens, Anchorage, Hyderabad, Philadelphia, San Francisco, San Juan, Honolulu, London, and Sao Paolo.
Across the 10 cities, we collected a total of 5.5M panoramas.
Importantly, all sensitive information, such as license plates and faces, are blurred prior to collection.
Training on paths that are geographically aligned, but temporally unaligned
We group all data based on their physical location and time of capture.
We create a training pair if we find a continuous path in a city where there exists 2 sets of captures located along the same path (within a distance threshold), but captured at different times (e.g, different dates, or even morning vs. afternoon of the same day).
This strategy forces CityRAG to disentangle the similarities (buildings, roads) and differences (weather, dynamics, lighting) between the pairs, such that it can reconstruct those similarities while maintaining a consistent transient appearance.
See video for details.
Results
The video for geospatial conditioning (left column), trajectory defined by the target video (right column), and the first image of the target video are provided as conditions.
The objective is to reconstruct the static structures (e.g., buildings, roads) from the geospatial condition, follow the trajectory, and respect the weather conditions and dynamic objects in the first image condition.
Non-trivial disentanglement of weather / cars (first image) and geometry (geospatial condition)
Follows the weather of the first image. Cars from the first image continue to move realistically. Buildings (e.g., the church) are correctly reconstructed under the desired lighting.
Non-pixel-aligned geospatial conditions and generations
Follows the input trajectory closely even when rotating at 180 degrees.
The buildings are rendered before appearing in the geospatial condition. Understands the structure of the scene, rather than relying on a pixel-aligned mapping.
The geospatial condition is a video stuck in traffic. CityRAG still generates a plausible sequence that follows the trajectory, showing its understanding of the scene layout.
Renders the white fence and green building on the right side of the road that appear in the geo conditioning later.
Understands the structure of the scene, rather than relying on a pixel-aligned mapping.
CityRAG generates a plausible sequence that follows the trajectory without additional context from the geospatial condition, showing its understanding of the scene layout.
Additional results
Baselines
To the best of our understanding, there are no open-source baselines that perform our task of generating a 3D-consistent, navigable environment while simultaneously adhering to an external spatial cache.
We run baselines from each of the categories: 1) I2V + pose control (Gen3C); 2) V2V + pose control (Gen3C, TrajCrafter); 3) V2V + style transfer (AnyV2V).
CityRAG can be considered a superset of these categories, while also possessing a strong understanding of scene content (static vs. transient) and layouts.
Inference via User Input and RAG
CityRAG allows users to navigate arbitrary trajectories that do not exist in the database by stitching multiple retrieved geospatial videos.
In this video example below, CityRAG retrieves and combines two perpendicular paths from the same intersection to construct a new trajectory that resembles turning right.
Despite the discontinuity in the geospatial condition frames, the generator produces a consistent video, indicating its robustness and its understanding of the static and transient elements in a scene.
Minutes-long navigation with arbitrary trajectories
By stitching geospatial videos, users can specify arbitary paths. Then, CityRAG generates consistent sequences via autoregressive generation (AR).
Note: CityRAG was not trained on AR. Consecutive generations simply take the last frame of the previous generation as the first image. Geospatial conditions ground each independent generation to ensure consistency (of the static structures).
Example
Top: Generated video (sped up 2x) of the streets of Philadelphia. Even though consecutive generations are linked only by one frame, the video (in particular the static structure) remains mostly stable. Each new generation is labeled by a green border. Bottom: Geospatial and trajectory conditions. The trajectory is arbitraily drawn and does not exist as a continuous video in the Street View database.
5 geospatial videos were retrieved and stitched, with each transition labeled in the "Retrieved geospatial #" counter.
Additional Results: Loop Closure
Athens
San Juan
Additional Results: Navigation
San Francisco
Paris
London
Limitations and Future Work
Autoregressive Generation
There can be noticeable artifacts between consecutive generations, as they are linked only by one image. Incorporating existing autoregressive methods could significantly improve stability and consistency.
Object-Oriented Control
We provide no heuristics to the model regarding static vs. transient objects — the disentanglement is completely data-driven.
However, if a lot of our paired training data (same location, different time) is close in time (e.g., same day capture), then parked cars on the side of the street, trees...etc could be interpreted as static objects.
Future work could include fine-grained control and annotations over individual elements in the scene to improve controllability and realism.
Data Biases
Although we collected data from 10 cities, across 4 continents, the majority of the data is located in Western countries. This could introduce representation bias. Though CityRAG is a research paper without direct use in products or applications, in the future, any follow up work should attempt to mitigate this bias via more diverse data collection or algorithmic corrections.
Acknowledgements
Gene Chou was supported by an NSF graduate fellowship (2139899).
We thank Gordon Wetzstein, Aleksander Holynski, Jon Barron, Dor Verbin, Pratul Srinivasan, Rundi Wu, Ruiqi Gao, Haian Jin, Linyi Jin, and Haofei Xu for discussions and support.
BibTeX
@misc{chou2026cityrag,
title = {CityRAG: Stepping Into a City via Spatially-Grounded Video Generation},
author = {Chou, Gene and Herrmann, Charles and Genova, Kyle and Deng, Boyang and Peng, Songyou and Hariharan, Bharath and Zhang, Jason Y. and Snavely, Noah and Henzler, Philipp},
year = {2026},
eprint = {2604.19741},
archivePrefix= {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2604.19741}
}